A interrupção global que derrubou sites, apps e serviços inteiros na manhã de 18 de novembro foi causada por um erro em um único arquivo distribuído pela Cloudflare.
A empresa confirmou oficialmente que não se tratou de um ataque e descreveu o ocorrido como um evento “profundamente doloroso” para sua equipe.
O incidente afetou plataformas como X, ChatGPT, Spotify e diversos serviços corporativos ao redor do mundo, tornando páginas indisponíveis ou extremamente lentas por horas.

O que é a Cloudflare e por que tantas empresas dependem dela?
A Cloudflare opera uma das maiores redes globais dedicadas a acelerar tráfego, distribuir conteúdo e filtrar ameaças digitais em tempo real.
Ela funciona como uma camada entre os servidores de um site e o usuário final, absorvendo picos de acesso, bloqueando atividades maliciosas e reduzindo a latência ao aproximar conteúdo de quem acessa. A infraestrutura cobre centenas de cidades e se integra a provedores, operadoras e serviços corporativos no mundo inteiro.
A presença massiva faz com que a companhia esteja embutida no funcionamento diário de milhares de plataformas, de redes sociais a sistemas bancários.
Inúmeros sites adotam a Cloudflare para lidar com grandes volumes de tráfego sem sobrecarregar seus servidores e para proteger APIs e aplicativos de ataques automatizados, inclusive o Adrenaline.
Estimativas de mercado apontam que a Cloudflare atende aproximadamente 20% de todos os sites ativos da internet, criando uma dependência direta entre sua infraestrutura e o funcionamento diário de plataformas globais
Por isso, quando algo falha nesse ecossistema, a interrupção deixa de ser pontual e atinge cadeias inteiras que dependem desse roteamento global.
Além da rapidez, outro aspecto que explica sua onipresença é o modelo que combina CDN, firewall, mitigação de bots e serviços de DNS em um único fluxo. Ao centralizar essas camadas num ponto único, empresas simplificam suas operações, mas também aumentam a dependência de que essa engrenagem funcione sem desvios.
A pane de 18 de novembro expôs exatamente essa interdependência.
Como a falha começou e por que parecia um ataque
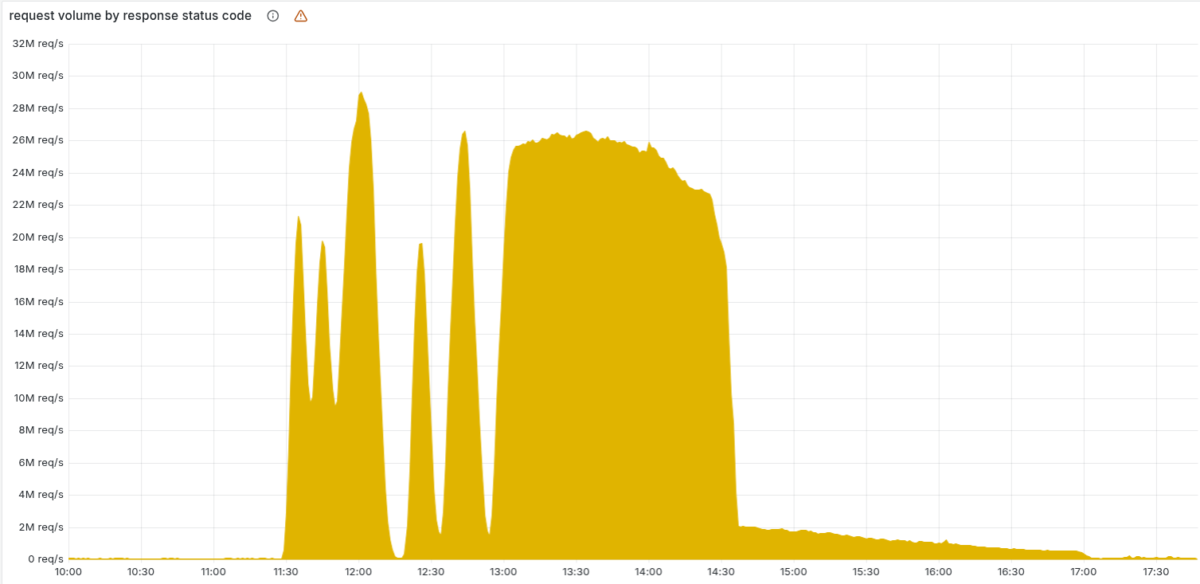
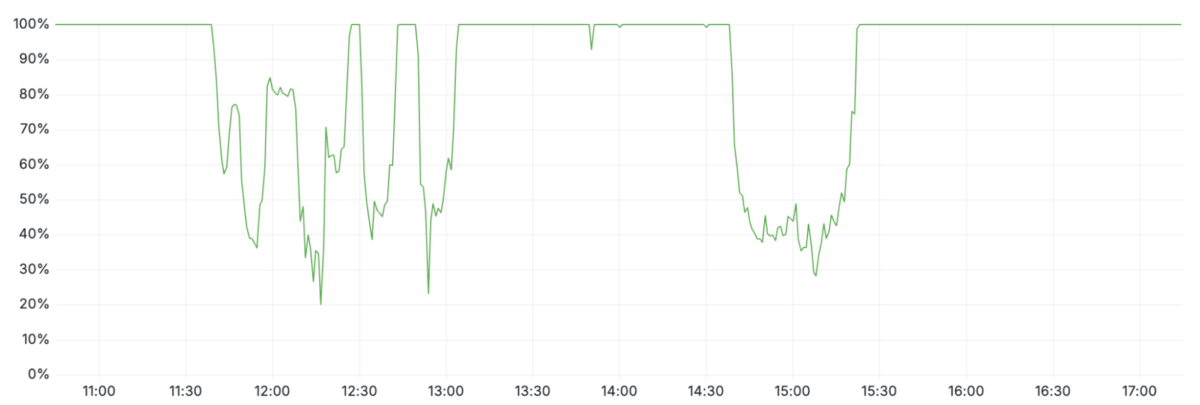
Pouco depois das 11h20 UTC (8:20 no Brasil), a Cloudflare viu seu tráfego despencar enquanto erros 5xx se espalhavam pela rede.
O comportamento intermitente, com ciclos de aproximadamente cinco minutos entre quedas e breves recuperações, confundiu a equipe técnica. O padrão lembrava um DDoS massivo, principalmente porque até a página de status (hospedada fora da infraestrutura da empresa) caiu por coincidência no mesmo período.
O cenário no momento alimentou a hipótese de que a companhia estava sob ataque coordenado. Dados internos mostravam conexões oscilando entre estados saudáveis e travados, o que reforçava a impressão de que uma força externa submetia o sistema a picos de carga.
No entanto, a causa era muito mais interna e prosaica: mudanças recentes num cluster de banco de dados ClickHouse alteraram permissões e passaram a gerar informações duplicadas ao montar o arquivo de recursos usado pela tecnologia de detecção de bots.
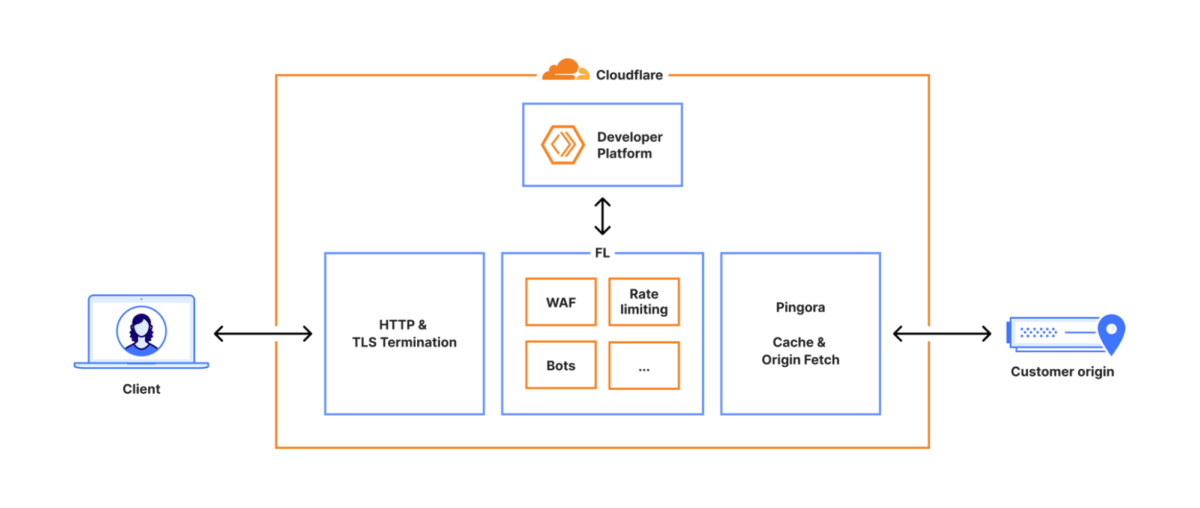
O arquivo que derrubou quase um terço da internet
O arquivo em questão reúne “features”, parâmetros usados pelo modelo de machine learning que classifica requisições suspeitas. Ele é atualizado automaticamente a cada poucos minutos e distribuído para toda a malha global.
Uma alteração de controle de acesso fez com que o banco de dados duplicasse metadados de tabelas durante a consulta que alimenta o arquivo. O resultado foi que o documento final dobrou de tamanho ao incluir centenas de linhas que não deveriam estar lá.
O software responsável por processá-lo tem um limite rígido de capacidade. Quando o arquivo ultrapassou a quantidade de features suportadas, o módulo de bots entrou em pânico e interrompeu o fluxo de requisições.
Como o arquivo era regenerado a cada cinco minutos, versões boas e ruins se alternavam enquanto a atualização avançava pelo cluster, criando a oscilação vista no início do incidente.
Em palavras da própria equipe, incluídas no meio da documentação interna do caso, “o padrão enganou parte do time porque a falha se resolvia por conta própria antes de voltar a aparecer, comportamento incomum para um problema de configuração”.
Impacto sobre os serviços e efeito cascata
Com o módulo quebrado, o proxy central da Cloudflare falhou, e qualquer solicitação que dependesse dele começou a retornar erros. Isso afetou:
- CDN e serviços de segurança
- Workers KV
- Cloudflare Access
- Turnstile
- Painel de administração
Alguns sistemas não chegaram a travar, mas ficaram inutilizáveis por perda de autenticação, lentidão extrema ou comportamento inconsistente.
O painel, por exemplo, continuou carregando, mas muitos usuários sequer conseguiam efetuar login devido à falha do Turnstile.
A detecção de spam em e-mails também sofreu redução temporária de precisão, e regras baseadas em bot score passaram a apresentar falsos positivos.
Como a equipe encontrou o problema e restabeleceu a rede
Às 10h05, as equipes iniciaram um desvio interno para aliviar a pressão sobre o Workers KV e o Access, reduzindo parte dos sintomas. A virada veio às 11h24, quando o time identificou definitivamente o arquivo de bots como origem do colapso e interrompeu sua geração automática, substituindo-o por uma versão estável.
Às 11h30, o tráfego global começou a voltar ao normal. A restauração completa, incluindo serviços remanescentes que haviam ficado em estados inconsistentes, terminou às 14h06.
Dane Knecht, executivo da empresa, se pronunciou afirmando que “hoje mais cedo, falhamos com nossos clientes e com a internet em geral. Sabemos o impacto real que isso gerou e vamos fazer o necessário para reconquistar essa confiança”.
O que acontece agora dentro da Cloudflare
A companhia iniciou uma revisão profunda dos processos que permitem que arquivos internos sejam distribuídos globalmente sem validações de segurança mais rígidas. Entre as medidas imediatas estão:
- Criação de bloqueios globais para impedir a propagação de arquivos defeituosos
- Revisão dos modos de falha de todos os módulos do proxy
- Ajustes para que relatórios de erro não consumam recursos a ponto de prejudicar o tráfego
- Fortalecimento da ingestão de configurações para evitar duplicações silenciosas
Embora a Cloudflare tenha passado por outros incidentes nos últimos anos, a empresa reconheceu que esta foi sua interrupção mais ampla desde 2019.
A falha expôs fragilidades no fluxo de configuração automatizado e reacendeu debates sobre como sistemas distribuídos podem sofrer impactos massivos a partir de erros pequenos.
Leia também:
- Steam foi alvo de ataque DDoS que também atingiu Riot, PlayStation e Xbox
- Roteadores TP-Link podem acabar sendo banidos nos EUA
- 14 grandes desastres com IA que chamaram a atenção
Quando um arquivo vira um ponto único de colapso
A interrupção de 18 de novembro mostrou como pequenas mudanças em ambientes distribuídos podem criar falhas globais mesmo em estruturas desenhadas para absorver problemas localizados.
A velocidade com que um arquivo defeituoso se propagou dá dimensão de como a internet moderna depende de automatizações em tempo real — e de como qualquer descuido nesses processos pode escalar rapidamente.
Será que não estamos dependentes demais de um oligopólio em que poucas empresas conseguem afetar tantos serviços ao mesmo tempo?
Fonte: Cloudflare

- Categorias

Participe do grupo de ofertas do Adrenaline
Confira as principais ofertas de hardware, componentes e outros eletrônicos que encontramos pela internet. Placa de vídeo, placa-mãe, memória RAM e tudo que você precisa para montar o seu PC. Ao participar do nosso grupo, você recebe promoções diariamente e tem acesso antecipado a cupons de desconto.
Entre no grupo e aproveite as promoções